
بالنسبة لخبراء تحسين محركات البحث (SEO) ، تعد تحديثات Google الأساسية طريقة حياة. تحدث مرة واحدة على الأقل – إن لم يكن عدة مرات – في السنة.
بالطبع سيكون هناك رابحون وخاسرون.
لذلك ، على الرغم من أن جوجل لا تكشف عن معظم عوامل الترتيب وراء تحديثات الخوارزمية ، هناك أشياء يمكننا القيام بها لفهم ما يحدث بشكل أفضل ، من حيث:
- ما هو محتوى الموقع المتأثر.
- المواقع العاملة في مساحة البحث الخاصة بك.
- أنواع النتائج.
الحد هو خيالك وأسئلتك (بناءً على معرفتك بـ SEO) وبالطبع بياناتك.
سيغطي هذا الرمز تجميعات مستوى صفحة نتائج محرك البحث (SERP) (مقارنة فئة المواقع المشتركة) ، ويمكن تطبيق نفس المبادئ على طرق العرض الأخرى في التحديث الرئيسي مثل أنواع النتائج (فكر مقتطفات ووجهات نظر أخرى مذكورة أعلاه).
استخدام Python لمقارنة SERPs
المبدأ العام هو مقارنة SERPs قبل التحديث الرئيسي وبعده ، مما سيعطينا بعض الأدلة على ما يحدث.
سنبدأ باستيراد مكتبات Python الخاصة بنا:
import re
import time
import random
import pandas as pd
import numpy as np
import datetime
from datetime import timedelta
from plotnine import *
import matplotlib.pyplot as plt
from pandas.api.types import is_string_dtype
from pandas.api.types import is_numeric_dtype
import uritools
pd.set_option('display.max_colwidth', None)
%matplotlib inlineمن خلال تعيين بعض المتغيرات ، سنركز على موقع ON24.com حيث فقدوا التحديث الرئيسي.
root_domain = 'on24.com' hostdomain = 'www.on24.com' hostname="on24" full_domain = 'https://www.on24.com' site_name="ON24"
عند قراءة البيانات ، نستخدم تصديرًا من GetSTAT يحتوي على تقرير مفيد يسمح لك بمقارنة SERPs لكلماتك الرئيسية قبل وبعد.
يتوفر تقرير SERP هذا من موفري تتبع الترتيب الآخرين مثل مراقبة تحسين محركات البحث و تصنيف الويب المتقدم – لا توجد تفضيلات أو موافقات من جانبي!
getstat_ba_urls = pd.read_csv('data/webinars_top_20.csv', encoding = 'UTF-16', sep = 't')
getstat_raw.head()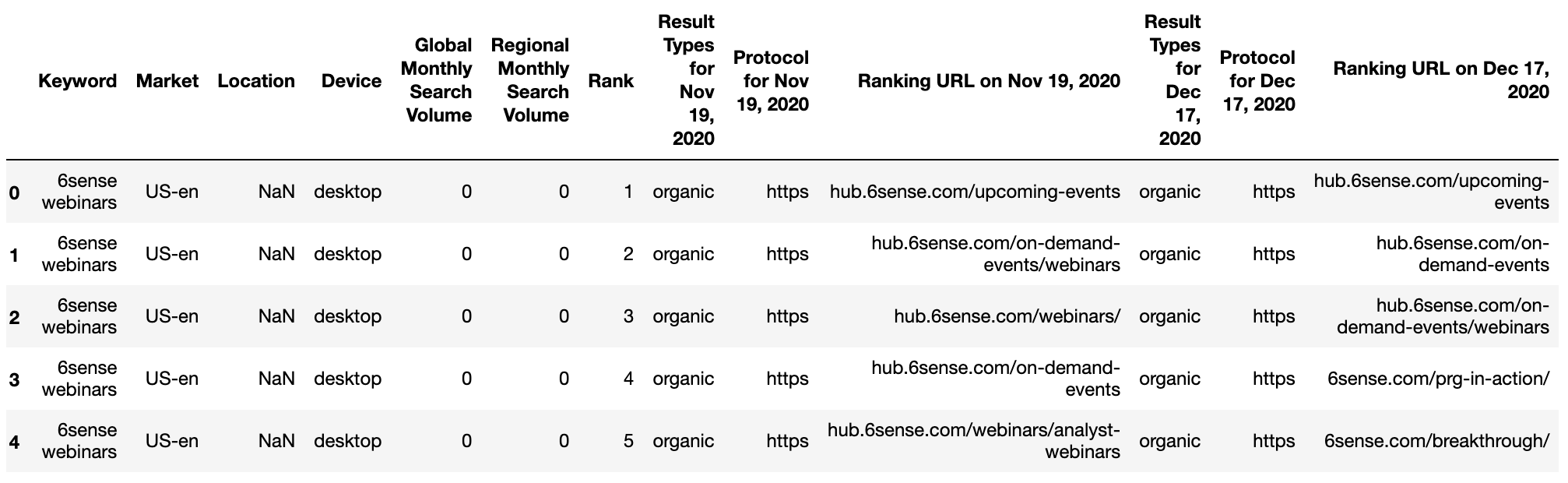 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022getstat_ba_urls = getstat_raw
أنشئ عناوين URL من خلال الانضمام إلى البروتوكول وسلسلة URL للحصول على عنوان URL للترتيب الكامل قبل التحديث وبعده.
getstat_ba_urls['before_url'] = getstat_ba_urls['Protocol for Nov 19, 2020'] + '://' + getstat_ba_urls['Ranking URL on Nov 19, 2020'] getstat_ba_urls['after_url'] = getstat_ba_urls['Protocol for Dec 17, 2020'] + '://' + getstat_ba_urls['Ranking URL on Dec 17, 2020'] getstat_ba_urls['before_url'] = np.where(getstat_ba_urls['before_url'].isnull(), '', getstat_ba_urls['before_url']) getstat_ba_urls['after_url'] = np.where(getstat_ba_urls['after_url'].isnull(), '', getstat_ba_urls['after_url'])
للحصول على نطاقات عناوين URL للترتيب ، نقوم بإنشاء نسخة من عنوان URL في عمود جديد ، وإزالة النطاقات الفرعية باستخدام عبارة if المضمنة في قائمة الفهم:
getstat_ba_urls['before_site'] = [uritools.urisplit(x).authority if uritools.isuri(x) else x for x in getstat_ba_urls['before_url']]
stop_sites = ['hub.', 'blog.', 'www.', 'impact.', 'harvard.', 'its.', 'is.', 'support.']
getstat_ba_urls['before_site'] = getstat_ba_urls['before_site'].str.replace('|'.join(stop_sites), '')يتم تكرار قائمة الفهم لاستخراج المجالات بعد التحديث.
getstat_ba_urls['after_site'] = [uritools.urisplit(x).authority if uritools.isuri(x) else x for x in getstat_ba_urls['after_url']]
getstat_ba_urls['after_site'] = getstat_ba_urls['after_site'].str.replace('|'.join(stop_sites), '')
getstat_ba_urls.columns = [x.lower() for x in getstat_ba_urls.columns]
getstat_ba_urls = getstat_ba_urls.rename(columns = {'global monthly search volume': 'search_volume'
})
getstat_ba_urls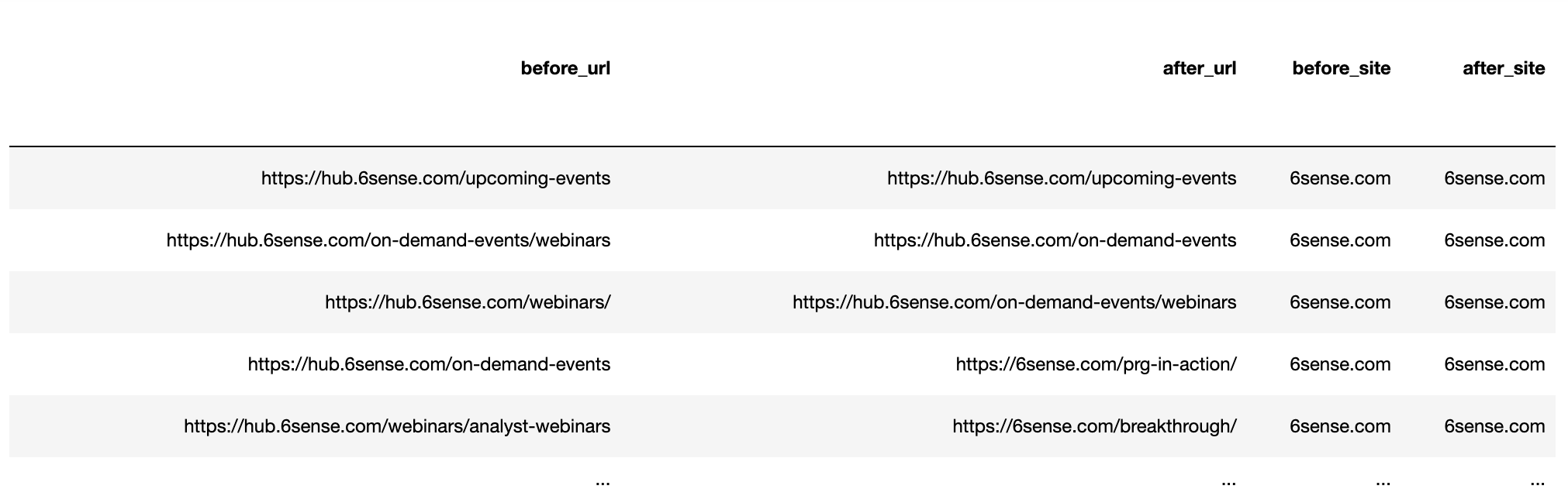 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022قم بإلغاء تكرار عناوين URL المتعددة للترتيب
تتمثل الخطوة التالية في إزالة تصنيف عناوين URL المتعددة حسب نفس المجال بواسطة كلمة بحث SERP. سنقسم البيانات إلى مجموعتين ، قبل وبعد.
بعد ذلك ، سنقوم بالتجميع حسب الكلمات الرئيسية ونقوم بإلغاء المكرر:
getstat_bef_unique = getstat_ba_urls[['keyword', 'market', 'location', 'device', 'search_volume', 'rank',
'result types for nov 19, 2020', 'protocol for nov 19, 2020',
'ranking url on nov 19, 2020', 'before_url', 'before_site']]
getstat_bef_unique = getstat_bef_unique.sort_values('rank').groupby(['before_site', 'device', 'keyword']).first()
getstat_bef_unique = getstat_bef_unique.reset_index()
getstat_bef_unique = getstat_bef_unique[getstat_bef_unique['before_site'] != '']
getstat_bef_unique = getstat_bef_unique.sort_values(['keyword', 'device', 'rank'])
getstat_bef_unique = getstat_bef_unique.rename(columns = {'rank': 'before_rank',
'result types for nov 19, 2020': 'before_snippets'})
getstat_bef_unique = getstat_bef_unique[['keyword', 'market', 'device', 'before_snippets', 'search_volume',
'before_url', 'before_site', 'before_rank'
]]
getstat_bef_unique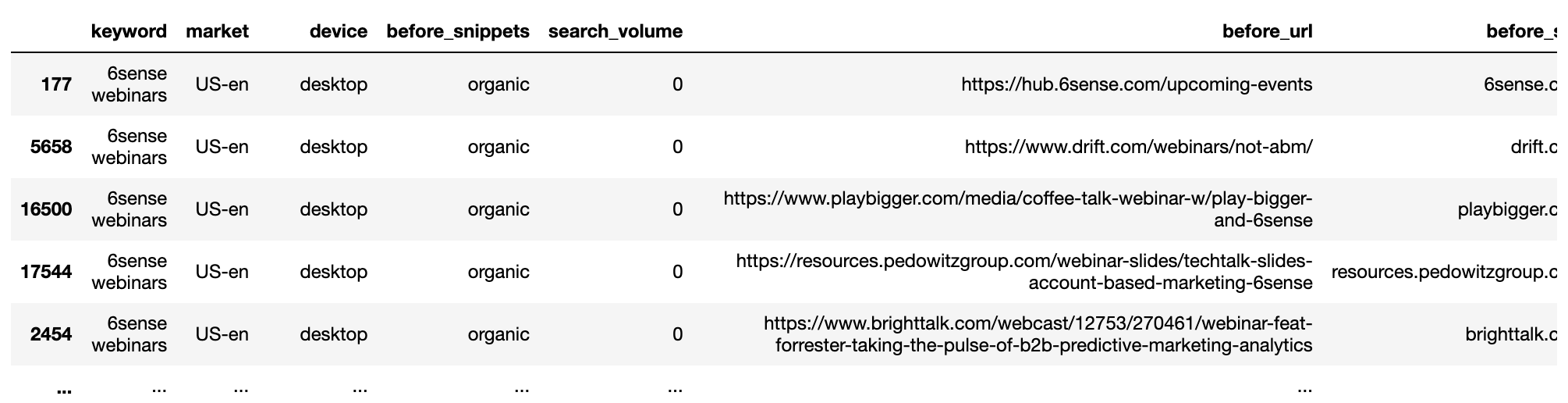 لقطة من قبل المؤلف ، يناير 2022
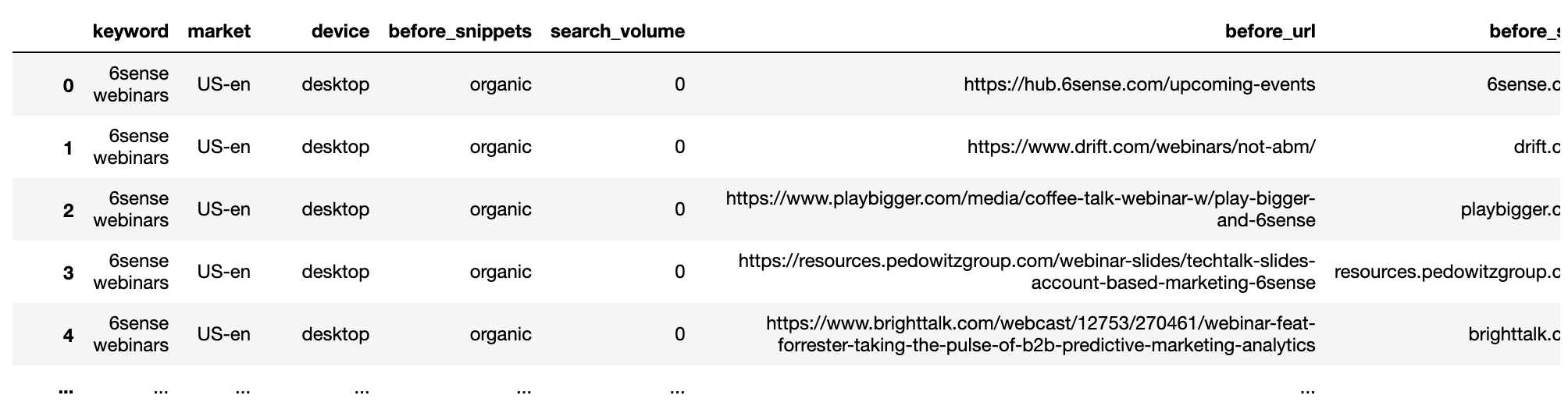
لقطة من قبل المؤلف ، يناير 2022يتم تكرار الإجراء لمجموعة البيانات التالية.
getstat_aft_unique = getstat_ba_urls[['keyword', 'market', 'location', 'device', 'search_volume', 'rank',
'result types for dec 17, 2020', 'protocol for dec 17, 2020',
'ranking url on dec 17, 2020', 'after_url', 'after_site']]
getstat_aft_unique = getstat_aft_unique.sort_values('rank').groupby(['after_site', 'device', 'keyword']).first()
getstat_aft_unique = getstat_aft_unique.reset_index()
getstat_aft_unique = getstat_aft_unique[getstat_aft_unique['after_site'] != '']
getstat_aft_unique = getstat_aft_unique.sort_values(['keyword', 'device', 'rank'])
getstat_aft_unique = getstat_aft_unique.rename(columns = {'rank': 'after_rank',
'result types for dec 17, 2020': 'after_snippets'})
getstat_aft_unique = getstat_aft_unique[['keyword', 'market', 'device', 'after_snippets', 'search_volume',
'after_url', 'after_site', 'after_rank'
]]تقسيم مواقع SERP
عندما يتعلق الأمر ب التحديثات الأساسية، عادة ما توجد معظم الإجابات في SERPs. هذا هو المكان الذي يمكننا فيه معرفة المواقع التي يتم مكافأتها وأيها تخسر.
مع إلغاء تكرار مجموعات البيانات وفصلها ، سنحدد المنافسين المشتركين حتى نتمكن من البدء في تقسيمهم يدويًا ، مما سيساعدنا في تصور تأثير التحديث.
serps_before = getstat_bef_unique serps_after = getstat_aft_unique serps_before_after = serps_before_after.merge(serps_after, left_on = ['keyword', 'before_site', 'device', 'market', 'search_volume'], right_on = ['keyword', 'after_site', 'device', 'market', 'search_volume'], how = 'left')
تنظيف أعمدة الترتيب من القيم الخالية (NAN ليس رقمًا) باستخدام وظيفة np.where () التي تعد مكافئ Panda لصيغة if في Excel.
serps_before_after['before_rank'] = np.where(serps_before_after['before_rank'].isnull(), 100, serps_before_after['before_rank']) serps_before_after['after_rank'] = np.where(serps_before_after['after_rank'].isnull(), 100, serps_before_after['after_rank'])
تم حساب بعض المقاييس لإظهار الفرق في الترتيب قبل مقابل بعد ، وما إذا كان عنوان URL قد تغير.
serps_before_after['rank_diff'] = serps_before_after['before_rank'] - serps_before_after['after_rank'] serps_before_after['url_change'] = np.where(serps_before_after['before_url'] == serps_before_after['after_url'], 0, 1) serps_before_after['project'] = site_name serps_before_after['reach'] = 1 serps_before_after
 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022اجمالي المواقع الفائزة
مع تنظيف البيانات ، يمكننا الآن التجميع لمعرفة المواقع الأكثر سيطرة.
للقيام بذلك ، نحدد الوظيفة التي تحسب متوسط الترتيب المرجح حسب حجم البحث.
ليست كل الكلمات الرئيسية مهمة بنفس القدر ، مما يساعد في جعل التحليل أكثر جدوى إذا كنت تهتم بالكلمات الرئيسية التي تحصل على أكبر عدد من عمليات البحث.
def wavg_rank(x):
names = {'wavg_rank': (x['before_rank'] * (x['search_volume'] + 0.1)).sum()/(x['search_volume'] + 0.1).sum()}
return pd.Series(names, index=['wavg_rank']).round(1)
rank_df = serps_before_after.groupby('before_site').apply(wavg_rank).reset_index()
reach_df = serps_before_after.groupby('before_site').agg({'reach': 'sum'}).sort_values('reach', ascending = False).reset_index()
commonstats_full_df = rank_df.merge(reach_df, on = 'before_site', how = 'left').sort_values('reach', ascending = False)
commonstats_df = commonstats_full_df.sort_values('reach', ascending = False).reset_index()
commonstats_df.head()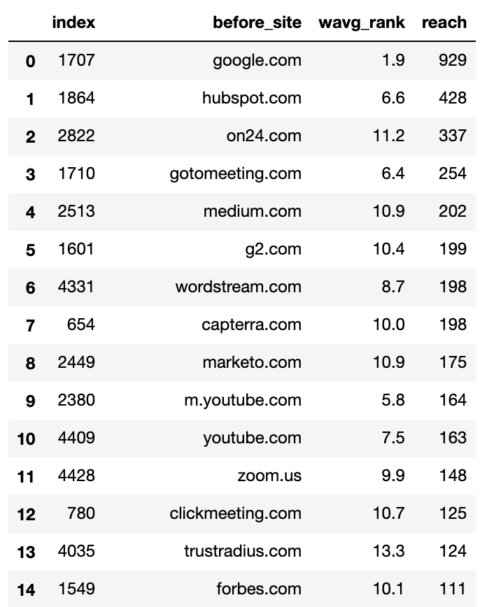 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022في حين أن التصنيف المتوسط المرجح مهم ، كذلك هو مدى الوصول لأنه يخبرنا عن مدى تواجد الموقع في Google ، أي عدد الكلمات الرئيسية.
يساعدنا الوصول أيضًا في تحديد أولويات المواقع التي نريد تضمينها في التقسيم.
يعمل التقسيم باستخدام وظيفة np.select التي تشبه صيغة Excel الضخمة المتداخلة.
أولاً ، نضع قائمة بشروطنا.
domain_conds = [ commonstats_df['before_site'].isin(['google.com', 'medium.com', 'forbes.com', 'en.m.wikipedia.org', 'hbr.org', 'en.wikipedia.org', 'smartinsights.com', 'mckinsey.com', 'techradar.com','searchenginejournal.com', 'cmswire.com']), commonstats_df['before_site'].isin(['on24.com', 'gotomeeting.com', 'marketo.com', 'zoom.us', 'livestorm.co', 'hubspot.com', 'drift.com', 'salesforce.com', 'clickmeeting.com', 'qualtrics.com', 'workcast.com', 'livewebinar.com', 'getresponse.com', 'superoffice.com', 'myownconference.com', 'info.workcast.com']), commonstats_df['before_site'].isin([ 'neilpatel.com', 'ventureharbour.com', 'wordstream.com', 'business.tutsplus.com', 'convinceandconvert.com']), commonstats_df['before_site'].isin(['trustradius.com', 'g2.com', 'capterra.com', 'softwareadvice.com', 'learn.g2.com']), commonstats_df['before_site'].isin(['youtube.com', 'm.youtube.com', 'facebook.com', 'linkedin.com', 'business.linkedin.com', ]) ]
بعد ذلك ، نقوم بإنشاء قائمة بالقيم التي نريد تخصيصها لكل شرط.
segment_values = ['publisher', 'martech', 'consulting', 'reviews', 'social_media']
ثم أنشئ عمودًا جديدًا واستخدم np.select لتعيين قيم له باستخدام قوائمنا كوسيطات.
commonstats_df['segment'] = np.select(domain_conds, segment_values, default="other") commonstats_df = commonstats_df[['before_site', 'segment', 'reach', 'wavg_rank']] commonstats_df
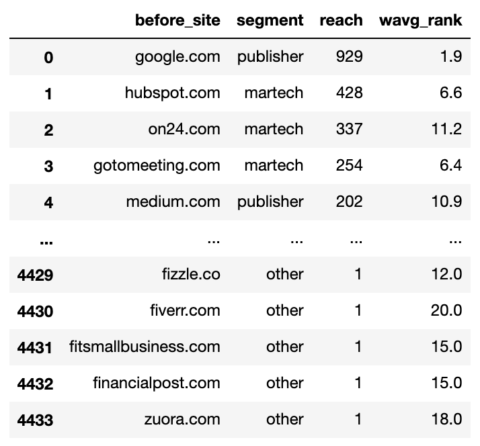 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022أصبحت المجالات الآن مجزأة ، مما يعني أنه يمكننا الاستمتاع بالتجميع المرح لمعرفة أي منها أنواع المواقع استفاد و تدهورت من التحديث.
# SERPs Before and After Rank serps_stats = commonstats_df[['before_site', 'segment']] serps_segments = commonstats_df.segment.to_list()
ننضم إلى البيانات الفريدة السابقة لـ SERP مع جدول شريحة SERP الذي تم إنشاؤه مباشرة أعلاه لتقسيم عناوين URL للترتيب باستخدام ميزة الدمج.
وظيفة الدمج التي تستخدم المعلمة “eft” تكافئ وظيفة Excel vlookup أو دالة مطابقة الفهرس.
serps_before_segmented = getstat_bef_unique.merge(serps_stats, on = 'before_site', how = 'left') serps_before_segmented = serps_before_segmented[~serps_before_segmented.segment.isnull()] serps_before_segmented = serps_before_segmented[['keyword', 'segment', 'device', 'search_volume', 'before_snippets', 'before_rank', 'before_url', 'before_site']] serps_before_segmented['count'] = 1 serps_queries = serps_before_segmented['keyword'].to_list() serps_queries = list(set(serps_queries)) serps_before_segmented
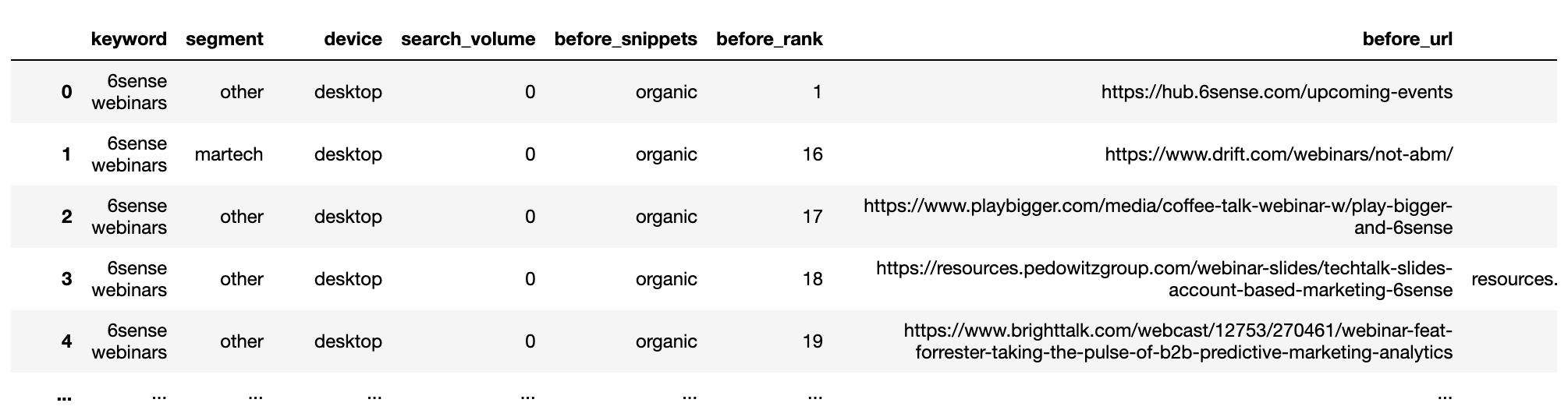 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022تجميع SERPs قبل:
def wavg_rank_before(x):
names = {'wavg_rank_before': (x['before_rank'] * x['search_volume']).sum()/(x['search_volume']).sum()}
return pd.Series(names, index=['wavg_rank_before']).round(1)
serps_before_agg = serps_before_segmented
serps_before_wavg = serps_before_agg.groupby(['segment', 'device']).apply(wavg_rank_before).reset_index()
serps_before_sum = serps_before_agg.groupby(['segment', 'device']).agg({'count': 'sum'}).reset_index()
serps_before_stats = serps_before_wavg.merge(serps_before_sum, on = ['segment', 'device'], how = 'left')
serps_before_stats = serps_before_stats.rename(columns = {'count': 'before_n'})
serps_before_stats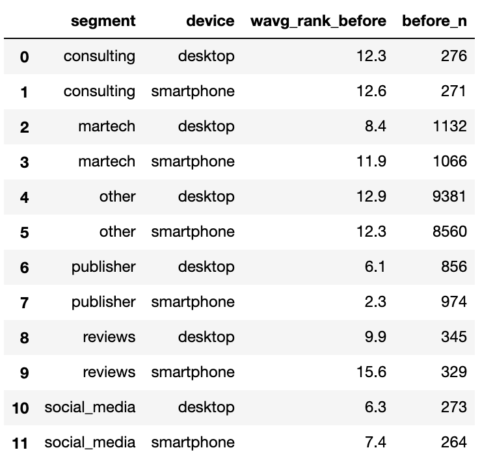 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022كرر الإجراء لـ SERPs بعد ذلك.
# SERPs After Rank
aft_serps_segments = commonstats_df[['before_site', 'segment']]
aft_serps_segments = aft_serps_segments.rename(columns = {'before_site': 'after_site'})
serps_after_segmented = getstat_aft_unique.merge(aft_serps_segments, on = 'after_site', how = 'left')
serps_after_segmented = serps_after_segmented[~serps_after_segmented.segment.isnull()]
serps_after_segmented = serps_after_segmented[['keyword', 'segment', 'device', 'search_volume', 'after_snippets',
'after_rank', 'after_url', 'after_site']]
serps_after_segmented['count'] = 1
serps_queries = serps_after_segmented['keyword'].to_list()
serps_queries = list(set(serps_queries))def wavg_rank_after(x):
names = {'wavg_rank_after': (x['after_rank'] * x['search_volume']).sum()/(x['search_volume']).sum()}
return pd.Series(names, index=['wavg_rank_after']).round(1)serps_after_agg = serps_after_segmented
serps_after_wavg = serps_after_agg.groupby(['segment', 'device']).apply(wavg_rank_after).reset_index()
serps_after_sum = serps_after_agg.groupby(['segment', 'device']).agg({'count': 'sum'}).reset_index()
serps_after_stats = serps_after_wavg.merge(serps_after_sum, on = ['segment', 'device'], how = 'left')
serps_after_stats = serps_after_stats.rename(columns = {'count': 'after_n'})
serps_after_stats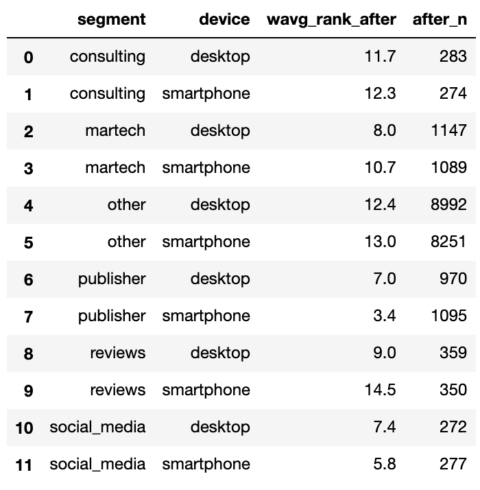 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022مع تلخيص اثنين من SERPs ، يمكننا الانضمام إليهم والبدء في إجراء مقارنات.
serps_compare_stats = serps_before_stats.merge(serps_after_stats, on = ['device', 'segment'], how = 'left') serps_compare_stats['wavg_rank_delta'] = serps_compare_stats['wavg_rank_after'] - serps_compare_stats['wavg_rank_before'] serps_compare_stats['sites_delta'] = serps_compare_stats['after_n'] - serps_compare_stats['before_n'] serps_compare_stats
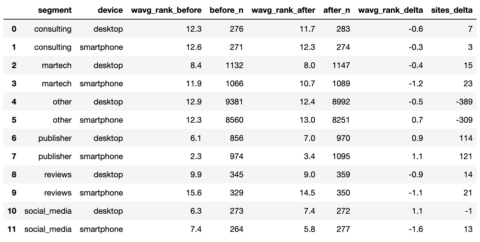 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022على الرغم من أننا يمكن أن نرى أن مواقع الناشرين يبدو أنها تحقق أكبر قدر من المكاسب بسبب تصنيف معظم الكلمات الرئيسية ، إلا أن الصورة ستظهر بالتأكيد 1000 كلمة أخرى في لعبة PowerPoint.
سنحاول القيام بذلك عن طريق إعادة تشكيل البيانات إلى تنسيق طويل تفضله حزمة Python “plotnine”.
serps_compare_viz = serps_compare_stats
serps_rank_viz = serps_compare_viz[['device', 'segment', 'wavg_rank_before', 'wavg_rank_after']].reset_index()
serps_rank_viz = serps_rank_viz.rename(columns = {'wavg_rank_before': 'before', 'wavg_rank_after': 'after', })
serps_rank_viz = pd.melt(serps_rank_viz, id_vars=['device', 'segment'], value_vars=['before', 'after'],
var_name="phase", value_name="rank")
serps_rank_vizserps_ba_plt = (
ggplot(serps_rank_viz, aes(x = 'segment', y = 'rank', colour="phase",
fill="phase")) +
geom_bar(stat="identity", alpha = 0.8, position = 'dodge') +
labs(y = 'Google Rank', x = 'phase') +
scale_y_reverse() +
theme(legend_position = 'right', axis_text_x=element_text(rotation=90, hjust=1)) +
facet_wrap('device')
)
serps_ba_plt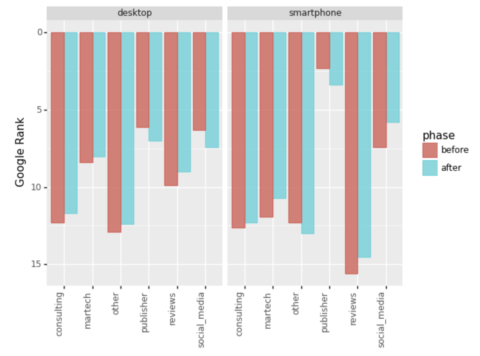 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022ولدينا تصورنا الأول ، والذي يوضح لنا كيف اكتسبت معظم أنواع المواقع في التصنيف ، وهو نصف القصة فقط.
لنلقِ نظرة أيضًا على عدد الإدخالات في أعلى 20.
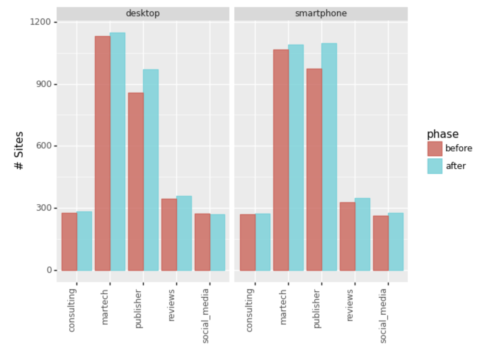 لقطة من قبل المؤلف ، يناير 2022
لقطة من قبل المؤلف ، يناير 2022تجاهل المقطع “الآخر” ، يمكننا أن نرى أن Martech والناشرين كانوا الفائزين الرئيسيين من خلال توسيع مدى وصول كلماتهم الرئيسية.
ملخص
استغرق الأمر القليل من التعليمات البرمجية لإنشاء مخطط واحد مع كل عمليات التنظيف والتجميع.
ومع ذلك ، يمكن تطبيق المبادئ لتحقيق وجهات نظر خاسرة ممتدة مثل:
- مستوى المجال.
- محتوى الموقع الداخلي.
- أنواع النتائج.
- نتائج أكل لحوم البشر.
- تصنيف أنواع محتوى URL (المدونات وصفحات العروض وما إلى ذلك).
ستحتوي معظم تقارير SERP على البيانات اللازمة لأداء العروض الموسعة أعلاه.
على الرغم من أنها لا تكشف بشكل صريح عن عامل التصنيف الرئيسي ، إلا أن المشاهدات يمكن أن تخبرك كثيرًا بما يحدث ، وتساعدك في شرح التحديث الأساسي لزملائك ، وتكوين فرضيات لاختبار ما إذا كنت من أقل الأشخاص حظًا في البحث. التعافي.
المزيد من الموارد:
الصورة المميزة: Pixel Hunter / Shutterstock
#تصور #الفائزين #والخاسرين #في #تحديث #Google #Core #باستخدام #Python
المصدر
تعليقات
إرسال تعليق